AI Readiness Assessment Framework: Evaluate Your Organization Across 4 Dimensions
Published: – Updated:
For many companies, AI remains a well-known but poorly understood technology. They might even have a clear business case worked out, but when it comes to the implementation – things get complicated.
To avoid this, it’s crucial to understand whether your organization is even ready for AI implementation.
An AI readiness assessment defines exactly that. It examines your organization across several dimensions and delivers a clear verdict along with practical recommendations. Aimprosoft’s AI readiness assessment framework includes four dimensions: data, processes, infrastructure, and governance.
This article walks through the thinking behind that framework. Why these four dimensions, how each is evaluated, how scores become recommendations, and what changes when the AI involved is generative.
What is an AI readiness assessment framework?
A framework is the rulebook that defines what an assessment evaluates and how it scores the findings. A well-designed organizational AI readiness framework makes two evaluations of the same case reach the same verdict, even when different consultants run them on different days.
A working framework defines three things.
- Scope of inquiry: Which aspects of the organization to evaluate, and which intentionally left out.
- Scoring logic: What raises or lowers the dimension score, and how the dimensions combine into a verdict.
- Decision rules: The thresholds at which the framework says GO, CONDITIONAL GO, or NO-GO.

Why four dimensions?
A four-dimensional framework we use at Aimprosoft is designed to produce a clear verdict on whether a specific AI initiative is ready to launch. It’s broad enough to grasp every category of failure and narrow enough for the whole process to fit within two to three weeks.
The scoring is rigorous enough to satisfy a CFO, a CISO, and an auditor.
- Dimension 1: Processes.
Does the work you want to support with AI run consistently enough?
- Dimension 2: Data.
Does AI learn from trustworthy and well-organized sources?
- Dimension 3: Infrastructure.
Can your infrastructure realistically support building, deploying, and sustaining the system?
- Dimension 4: Governance.
Will the deployment stay defensible to regulators and users over time?
How each dimension gets scored
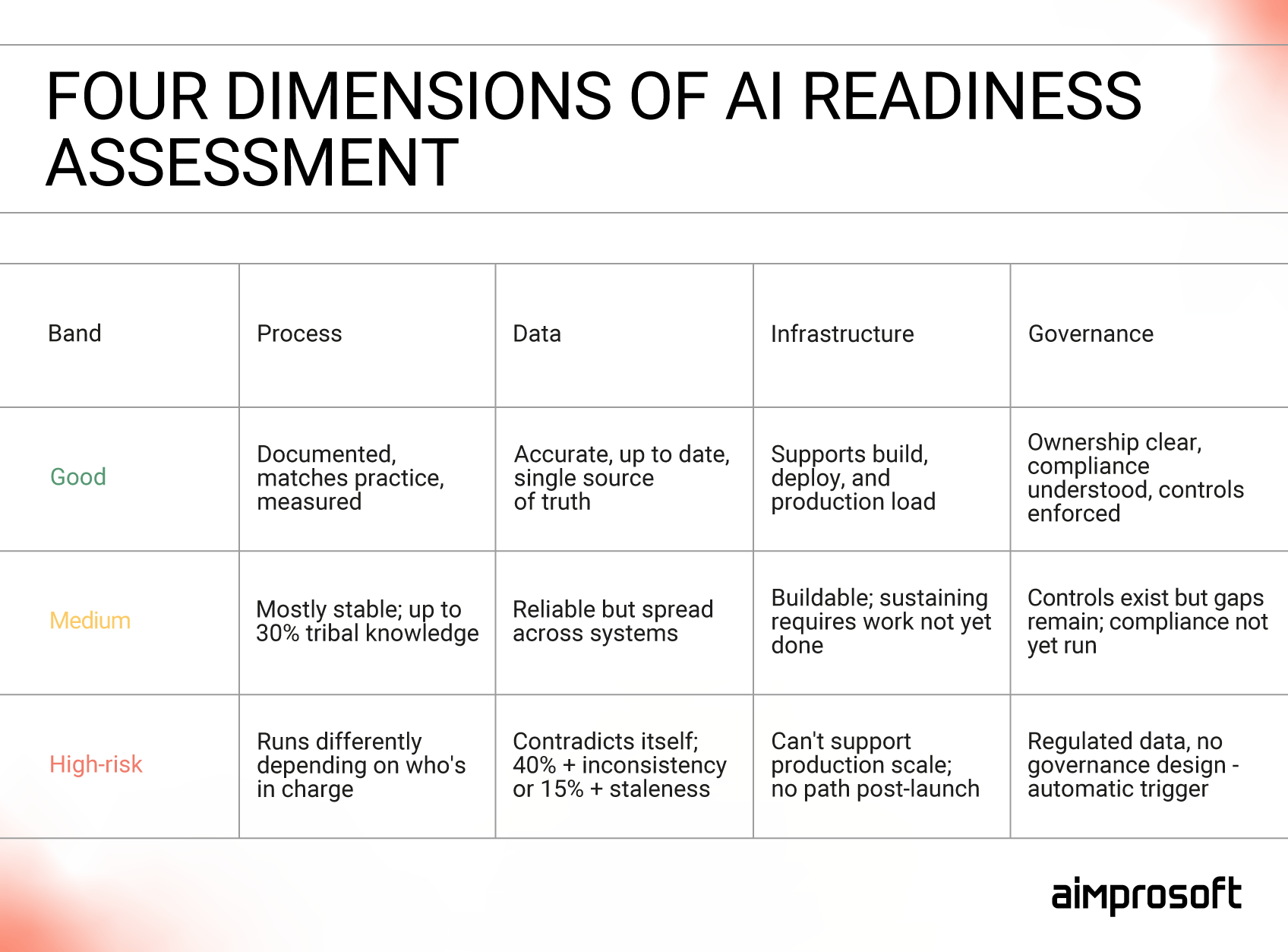
When evaluating AI readiness assessment components, we rate each one independently on a three-band scale: high-risk, medium, and good. The bands aren’t percentages or composite numbers – they are defined thresholds, designed so that the same evidence produces the same rating regardless of who is scoring. Here is what each band requires across dimensions.
Process maturity
What the assessment evaluates: Whether the workflow that the AI will support consistently runs the same way. The assessor maps the workflow end-to-end, identifies the exception paths, and traces who handles each exception and on what authority.
What evidence we gather: Process documentation, exception logs, workflow tooling output, and interviews with the people who run – not only manage – the process.
Scoring bands:
- Good: The workflow is documented, the documentation matches practice, exceptions are handled by defined rules, and the process is measured.
- Medium: The workflow is mostly stable, but a significant share of decisions still relies on individual judgment that is not written down. Up to 30% of tribal-knowledge dependency is considered a medium marker.
- High-risk: The workflow runs differently depending on who’s in charge. Exceptions are handled ad hoc. A measurement of “correct” doesn’t exist.
Knowledge and data quality
What the assessment evaluates: Whether the data the AI will draw on is available, accurate, consistent across sources, and authoritative.
What evidence we gather: Data sample reviews, source-system inventories, ownership maps, and update-cadence records. The assessor samples representative datasets, looks for contradictions between sources, and traces every “source of truth” claim back to whoever maintains the master record.
Scoring bands:
- Good: The data for a use case is available, accurate, and up to date. There is a clear owner and a single authoritative source.
- Medium: The data is mostly reliable, but it is spread across systems, and mediating it requires manual effort or institutional knowledge.
- High-risk: The data contradicts itself across sources. Key fields are stale, or the “source of truth” turns out to be several conflicting documents or one employee. 40% document contradiction and 15% staleness are considered high-risk markers.
Access and governance
What the assessment evaluates: Whether the AI system can be deployed and operated within the organization’s real compliance, security, and access constraints.
What evidence we gather: Policy documents, access-control configurations, sample compliance reviews of comparable systems, and interviews with legal, compliance, and information security.
Scoring bands:
- Good: Data ownership is clear, and access controls are enforced. Compliance requirements for the use case are understood. Governance is designed into the architecture from the start.
- Medium: The controls mostly exist but have gaps that surface under real-world load. The compliance review has not yet been run against the specific use case.
- High-risk: The use case touches regulated data without a governance design, lacks an audit trail, or has not engaged compliance at all. A regulated-data workflow without a governance design is an automatic high-risk trigger.
Technical constraints
What the assessment evaluates: Whether the existing infrastructure can support the planned AI system through build, deployment, and operation at production load.
What evidence we gather: Architecture diagrams, current production-system load metrics, and dependency inventories. Interviews with the infrastructure and platform teams.
Where the use case involves real-time inference or large-scale retrieval, we check whether the latency budget is realistically achievable on the existing infrastructure.
Scoring bands:
- Good: The infrastructure can integrate, deploy, and sustain the system at the expected production load. The team has the MLOps tooling to keep it running.
- Medium: The system can be built, but sustaining it in production will require new tooling, additional pipeline capacity, or integration work that is understood but not yet done.
- High-risk: The infrastructure can’t support the system at production scale. Key integrations do not exist. There is no realistic path to operating the system after launch.
How the four dimensions interact
When summing up AI readiness assessment criteria to reach a verdict, we apply the decision rules. Averaging doesn’t work here – the dimensions interact, and that is where most failures hide. These are the most common interaction examples.
Clean data, messy process: An AI is drawing on well-organized, accurate data, but the workflow it supports is full of undocumented exceptions and judgment calls. It’s easy to foresee with a great data score in the assessment.
As a result, the pilot launches, then underdelivers, and the team loses months wondering why a system built on good data isn’t delivering.
Solid process, weak data: The opposite problem – a mature and well-run process fed by data that contradicts itself from one source to another. The result is a system that behaves predictably and still can’t be trusted.
Strong infrastructure, weak governance: Even a confidently built and deployed system requires proper governance. Without it, it’s unclear who’s allowed to access what, how compliance signs off, and what the audit trail looks like.
Governance gaps don’t surface during a sandbox pilot. But at launch, when regulators show up, the whole thing can stall one step before going live. As the EU AI Act tightens and large buyers start demanding ISO/IEC 42001 certification in their contracts, this is happening more often than before.
Strong scores on three dimensions with a critical weakness on the fourth is a NO-GO until the interacting weakness is closed.
How scoring becomes the recommendation
The AI readiness framework ends with a recommendation: GO, CONDITIONAL GO, or NO-GO.
- GO: Every dimension lands in the good band, with no critical blockers. You’re ready to move into a pilot as-is.
- CONDITIONAL GO: One or two dimensions fall into the medium band, each with a fix that the organization can realistically complete within a set timeframe. Nothing is high-risk. You receive a sequenced remediation plan and a point to re-check before proceeding.
- NO-GO: At least one dimension is high-risk with no way to mitigate it, or two dimensions interact to create a significant blocker. This isn’t a dead end. The assessment presents a gap analysis that clarifies what would have to change for the answer to become yes.
From our experience, CONDITIONAL GO is the most common result. Most organizations aren’t fully ready, but they are solid on most dimensions with a couple of specific, fixable gaps.
Along with a verdict, we provide artefacts that leadership can act on – the scorecard, the gap and risk analysis, and the KPI baseline. GO and CONDITIONAL GO recommendations also include a pilot blueprint. We cover those deliverables in detail in our AI readiness assessment guide.

What changes for generative AI readiness assessment
The four-dimensional AI readiness assessment methodology works for generative AI too, though it adds four checks that traditional machine-learning deployments do not require.
- Hallucination rates. A predictive model has a single error rate, which can be compared with the ground truth. A generative model adds a second failure mode – hallucination.
Before you put a generative system near a regulated or high-stakes process, you need an acceptable hallucination threshold, a way to measure it, and a test that proves you’re safely under it.
- RAG as a requirement for regulated use cases. RAG is now a baseline for anything with compliance exposure. The Swedish Data Protection Authority identified RAG along with confidence thresholds and human review as ways to meet GDPR’s accuracy requirement in generative systems.
RAG also helps avoid hallucination problems. The infrastructure dimension includes additional checks on whether you can run RAG at the required scale.
- ISO/IEC 42001 in procurement contracts. Published in 2023 as the first international standard for AI management systems, it’s increasingly written into enterprise buyer requirements. The access and governance dimension maps your governance against the ISO/IEC 42001 controls.
- Mandatory human oversight for high-stakes use cases. In legal, medical, and financial deployments, human review is a fundamental requirement. The generative AI readiness assessment framework scores a missing human-in-the-loop design as a critical blocker on the governance dimension.
AI readiness assessment: Best practices
Treat people as the primary source of information. Only fill scoring bands after conversations with people who run the process, manage the data, and own compliance evidence. When you solely rely on documentation, it’s a desk audit, not an AI readiness evaluation.
Never average the scores. A 3.5 average across AI readiness assessment checklist can mean very different things. Four 3.5s is a GO. A 4-4-4-2 with a critical blocker on the weak dimension is a NO-GO. Averaging makes blockers invisible, and they only surface at launch.
Treat NO-GO as the most valuable answer you can get. A NO-GO verdict before the budget is committed is the most valuable outcome an AI readiness assessment can deliver. It comes with improvement recommendations, a clear view of what needs fixing, and your budget and reputation still intact.
Key takeaways
- AI readiness assessment frameworks are the rulebooks. Their job is to produce the same verdict from the same evidence, no matter who runs the assessment.
- Aimprosoft’s framework uses four dimensions – processes, data, infrastructure, and governance.
- Dimensions are scored independently and combined through conditional decision rules, never a single average.
- The interactions between dimensions are the most consequential findings on the framework.
- The framework outputs one of three recommendations – GO, CONDITIONAL GO, or NO-GO.
See how Aimprosoft applies this framework in a live assessment


