RAG vs LLM Fine-Tuning: How Enterprises Should Choose the Right AI Approach
Published: – Updated:
Once teams move beyond basic LLM use, the same challenge tends to surface: the model doesn’t quite fit the job. It doesn’t know your data. It doesn’t sound like your brand. It can’t keep up with how fast things change. Fine-tuning has long been the answer to that. But as RAG grows in adoption, a new question comes up RAG vs LLM fine-tuning?
These approaches are often treated interchangeably, but they solve different problems and treat them as alternatives to each other is where most teams get into trouble. If your AI system needs fresh knowledge, fine-tuning will not help. If it needs consistent behavior, RAG may fall short. And if it requires reasoning or actions, neither is enough on its own.
This article is here to introduce these approaches: what each solves, what it costs, and how to determine which—or both—align with your goals.
What is LLM fine-tuning?
Fine-tuning retrains a base model on your own curated examples — teaching it to produce responses that match your domain, structure, and tone. Whether it’s healthcare, finance, or education, the model reflects a fixed snapshot of that data at the time of training, which requires periodic retraining as knowledge evolves. It also involves preparing high-quality datasets, running training cycles, and maintaining the model over time.
What you get in return is a model that works faster, stays consistent at scale, and handles high-volume repeatable tasks without constant prompt engineering or output cleanup.
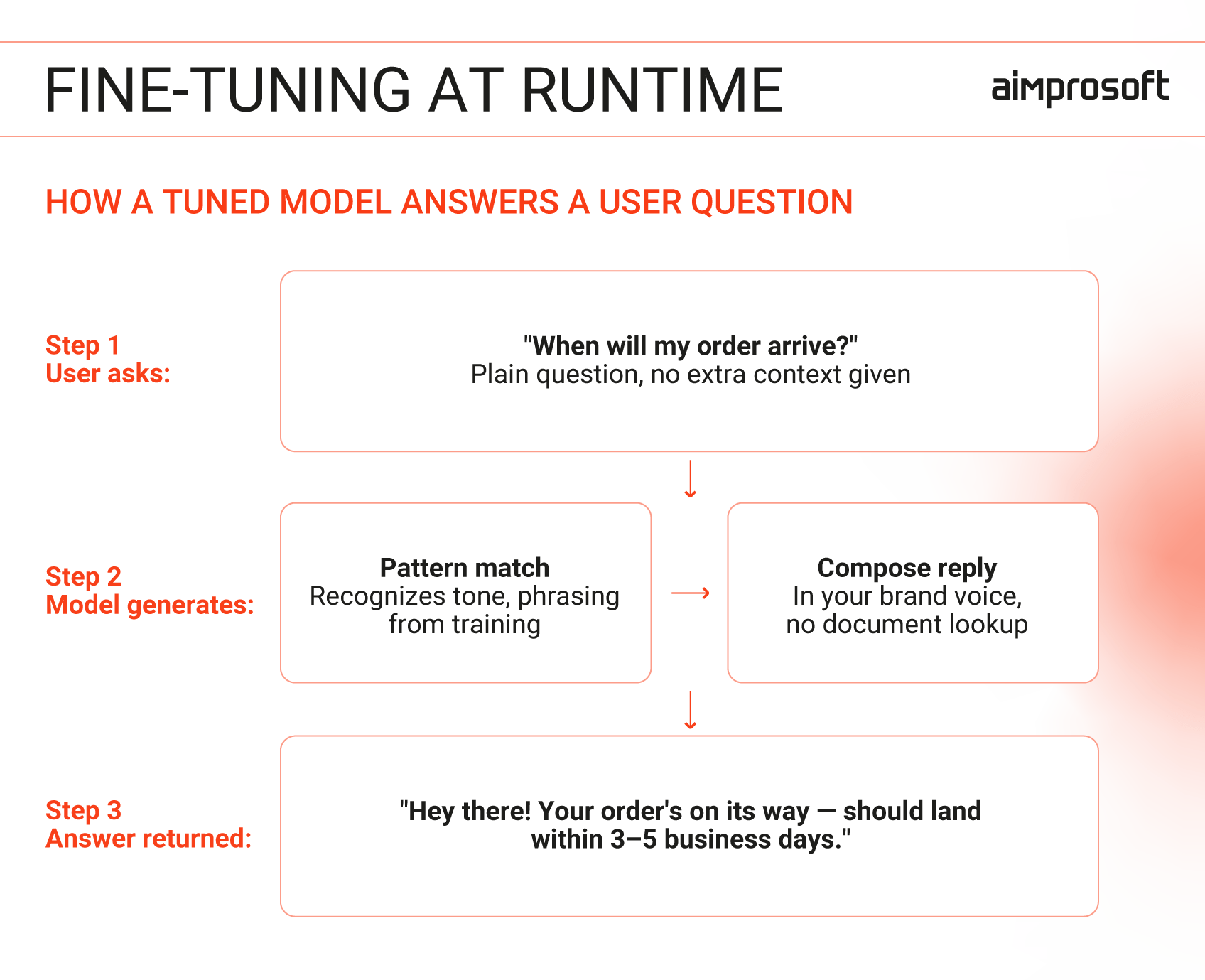
What is RAG?
RAG connects a generic LLM to your internal data through a retrieval layer. Instead of relying on what it learned during training, the model searches your documents when a question is asked —pulling the most relevant pieces and using them as context to build the answer every time. This way, you get updated information without updating the model itself.
For the business, this means faster deployment and the ability to ground responses in controlled sources, making it easier to update, trace, and scale as data changes.
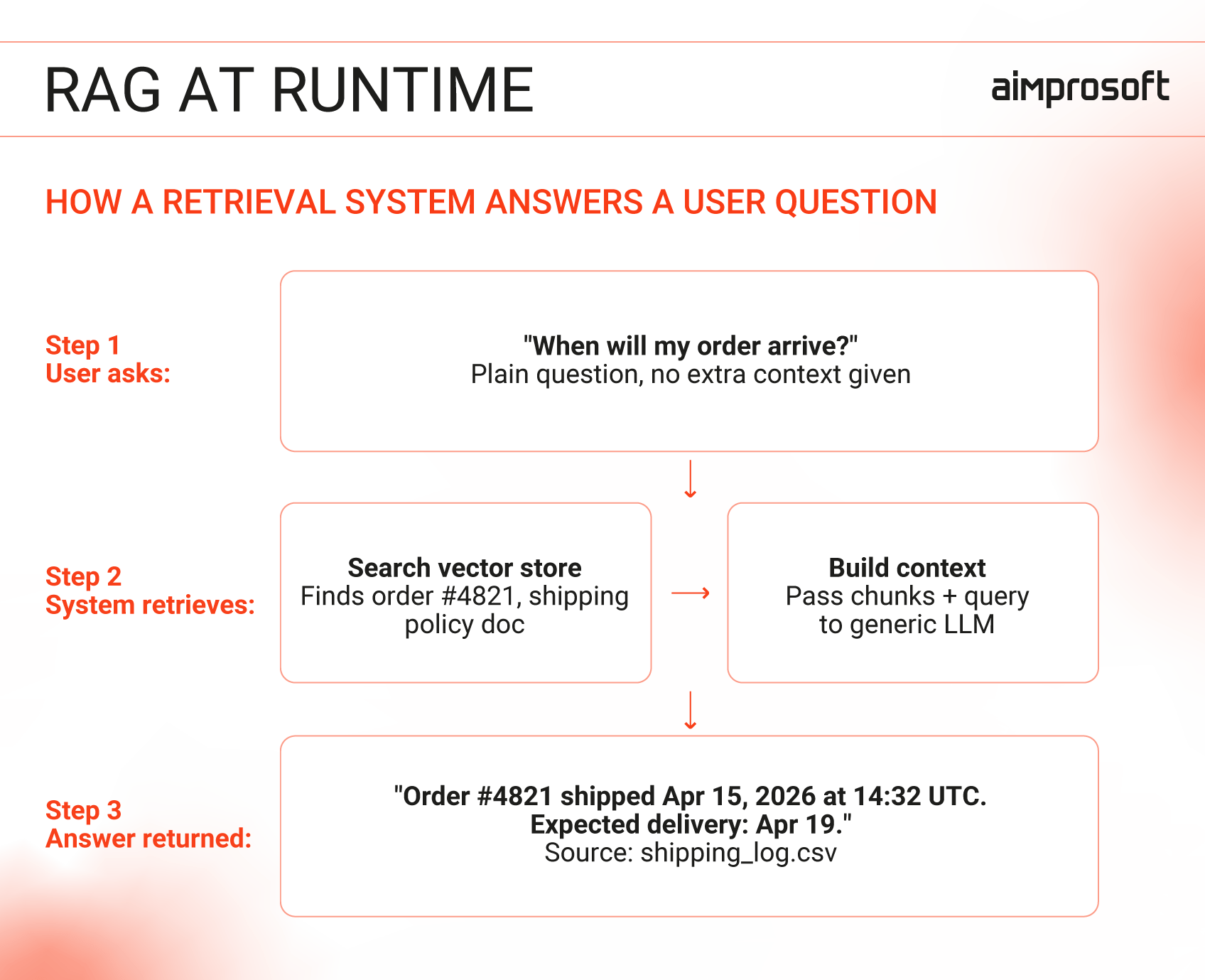
When to use RAG vs fine-tuning LLM?
The key difference between LLM fine-tuning vs. RAG lies in what each one actually does to—or for—the model.
RAG controls what the model sees. Fine-tuning controls how it behaves.
So your question should start with your needs, not with who wins in the LLM vs. RAG battle.
- Do you need up-to-date, traceable knowledge? RAG is built for this. It pulls answers directly from your latest documents, making it ideal for dynamic environments like live policies or frequently updated data. Since there’s no model training involved, deployment is faster. Keep in mind, though, that the model only works with what your documents contain — if the answer isn’t there, it won’t be in the response either.
- Do you need consistent, predictable behavior? Fine-tuning is the answer. It excels at enforcing tone, format, or reasoning patterns for specific, stable tasks (e.g., document classification or structured Q&A). Once trained, the model delivers answers directly, without the need to search through documents for every query.
These signals may seem straightforward, but that’s precisely the problem, most teams read them quickly and move straight to implementation. And in more cases than not, they apply the right approach to the wrong problem.
We’ve seen this play out in the same patterns:
- Trying to fix outdated knowledge with fine-tuning – the model is still wrong, just more confident.
- Expecting RAG to enforce structured output – retrieval provides content, not format.
- Treating weak prompts as a reason to train – the issue isn’t the model, but how it’s being used.
In each case, the system doesn’t fail immediately. It’s just that teams often move straight to implementation without clarifying their core problem. Whether it’s a knowledge gap, a formatting need, or a behavioral inconsistency. Knowing the root cause helps you select the right tool for the job.
LLM vs RAG: 4 questions to align your approach with your needs
Most businesses start with what they can resource. Meaning: we have ML engineers, so we fine-tune; we don’t, so we go with RAG. That’s understandable, but resource availability alone rarely tells the full story. Some situations call for one, some for the other, and some for both working together. Before committing on your setup, these four questions will help you understand what your problem actually needs.

1. How often does your knowledge change?
If your AI relies on information that changes often, you’re not just working with data — you’re working with live data. And this is where the choice of approach matters the most.
Fine-tuning infuses the model’s weights with knowledge during training. Once training ends, the model is “static”. It’s not a flaw. This mechanism enables the LLM to answer quickly and consistently. It also reduces the risk of “catastrophic forgetting” (where new learning overwrites prior knowledge).
But policies evolve continuously, and even with aggressive retraining cycles (weekly, monthly); you’re always shipping a model that’s already slightly behind. And retraining requires data collection, fine-tuning runs, evaluation, and deployment. By the time the new version is live, something else has likely shifted.
RAG doesn’t update the model itself. It retrieves your data at the moment when a question is asked. When a query comes in, the system searches your data sources and pulls the most relevant pieces. Those are passed to the model along with the question, and the answer is generated based on that context.
To update necessary data, you change the source document, the vector embeddings get re-indexed (a process that takes minutes, not days), and the next query automatically retrieves the updated chunk. Which makes it a logical choice.
NOTE! RAG is only as current as your data pipeline. If a document is updated but hasn’t been re-indexed yet, the old version can still show up. And if the wrong chunk is retrieved, the model will give a confident answer based on incorrect information.
2. Factual accuracy or behavioral consistency?
These points might seem obvious: Factual accuracy is about what the model knows, behavioral consistency is about how it responds. Yet, in practice, teams often address the symptoms rather than the root cause.
For example, if a model gives conflicting answers to the same question depending on phrasing or invents details from your systems. The instinct is to fix the model itself and try fine-tuning, when the real problem is missing knowledge.
The opposite is equally common. A model might provide accurate answers but fail to follow your required format in some responses. This inconsistency feels like a behavioral flaw, like it’s “doing something wrong.” But in many cases, the behavior is fine, the model is simply working with an incomplete or outdated context.
Before deciding which approach to use, look at how the system fails, not just what it produces.
3. Do responses need to be audited?
In regulated industries, being up to date isn’t enough; your answers need to be traceable. And RAG makes it possible. Every response is grounded in a retrieved document, the one you control, version, and can point out directly.
Fine-tuned models absorb knowledge during training, and after that, the source documents are no longer part of the process. The model that knows things, but there’s no live connection back to where it learned them. You can’t point to a document or a date. The knowledge is just in there.
For internal tools or low-stakes applications, that’s fine. For anything touching financial advice, medical information, legal interpretation, or regulated customer communications, it becomes a liability. If your compliance team needs to explain your system to a regulator, factor that into your decision before you build — not after.
4. Open-ended answers or structured, formatted output?
Some AI tasks are inherently open-ended: summarization, Q&A, drafting, and explanation. Others require strict structure: extracting fields, classifying intent, generating JSON files, filling templates, and producing consistent reports.
The difference matters more than it seems.
RAG works best when the goal is to generate grounded, flexible answers. It retrieves relevant context and lets the model synthesize a response. It helps you get the right answer, but not necessarily in the right format.
Fine-tuning, on the other hand, excels when the output format is non-negotiable. A model trained on thousands of correctly formatted examples stops needing to be told what the output should look like — it just produces. At high volume, that consistency becomes a real operational advantage.
If your use case requires both — grounded information and strict output structure — this is where combining approaches becomes natural.
Let’s talk
RAG vs fine-tuning: Which one reduces hallucinations?
“Which approach reduces hallucinations?” is one of the most common questions enterprises bring into AI-related conversations. It’s also one of the most misunderstood, because the answer isn’t LLM fine-tuning vs RAG. Both approaches can help reduce hallucinations, but neither eliminates them entirely.
Fine-tuning makes models more consistent, not more accurate. That’s where many teams go wrong. When the model produces wrong outputs, it feels like it needs more training, more examples, more domain exposure. It makes sense, only it doesn’t fix the root issue.
Fine-tuning shapes how a model behaves, not what it knows. When a fine-tuned model is wrong, it’s wrong confidently, fluently, and in exactly the voice you trained it to use. That combination is the most dangerous failure mode in the AI production.
RAG reduces factual hallucinations, but only when retrieval works. RAG grounds its responses in the given knowledge, all the documents, and internal data you feed it. So when there’s a response, it’s synthesized from retrieved content. When it’s wrong, you can point out what it retrieved, fix the source, and systematically improve the output. But RAG isn’t 100% hallucination-proof. If retrieval surfaces the wrong chunks, the model will still answer — just with bad source material instead of no source material.
Neither approach fixes hallucinations by itself. It comes down to how well your retrieval works, how often you test the system, and where you add human oversight.
Where does each approach break?
Both RAG and fine-tuning work well when used for the right problem. But every tool has its limits, and knowing where each one tends to break is just as important as knowing where it fits.
Where RAG breaks
RAG works well when it has access to clean, well-structured, and up-to-date information. This fact is also its Achilles’ heel. RAG starts to break when there is:
- No single source of truth: The same information exists in multiple places, and not all of it matches. The system may pull an outdated or conflicting version, which leads to answers that seem correct but aren’t reliable.
- Surface-level retrieval: The system returns content that looks relevant based on keywords but doesn’t really match the question’s intent. This usually happens when poorly structured or overly broad documents are chunked in a way that breaks context, leading to misleading answers.
- Weak access control: The system doesn’t properly limit what each user can see. This can expose sensitive information or return answers that aren’t appropriate for that user.

Where fine-tuning breaks
Fine-tuning works well when the problem is stable and well-defined. But once the environment starts changing, its limitations become clear. Fine-tuning starts to break when there is:
- Outdated training data: The underlying data or business rules change, but the model continues relying on what it learned during training, leading to responses that are no longer accurate.
- No feedback and update loop: When there’s no consistent process for collecting new examples and retraining the model, errors start to accumulate instead of being corrected.
- Mismatch between change and retraining speed: The business evolves faster than the model can be updated, making it increasingly misaligned with real-world needs.
- Hard-to-correct behavior: Even small changes require retraining the model, so fixing specific mistakes or adjusting outputs becomes slow and resource-intensive.
What’s cheaper: LLM fine-tuning or RAG?
Cost justification for AI systems isn’t one-size-fits-all. Whether you’re considering RAG, fine-tuning, or both, the true cost emerges over time — factors include data updates, infrastructure, and team effort. A one-year timeline shows what it costs to build, but not what it costs to maintain. Things like retraining cycles, retrieval infrastructure, and ongoing data work don’t fully show up at first, but after a few years, they become a significant part of the total cost.
The right choice depends on your use case, not just the initial price tag. To showcase, we’ve prepared three potential scenarios.
Scenario A
Low volatility and high volume. Knowledge changes quarterly or less. 30,000+ queries per day. Narrow, stable task.
Fine-tuning is the right call. The upfront cost is real, but there’s no retrieval overhead dragging on every query. By month 18 or so, the per-query savings start eating through the training investment. With two retraining cycles a year, fine-tuning typically becomes cheaper over three years.
Scenario B
Moderate volatility and moderate volume. Knowledge changes monthly. 5,000–50,000 queries per day. This is the most common enterprise situation.
RAG wins here. Six to eight retraining cycles over three years isn’t just expensive in compute but in engineering time, and in the gap periods where your model is running on information, it no longer quite knows is outdated. RAG’s infrastructure costs are real, but they’re predictable. Over three years, RAG typically becomes cheaper, mostly from avoided retraining and lighter ML engineering overhead.
Scenario C
High volatility, any volume. Knowledge changes weekly or faster. Live data, real-time pricing, and policy that shifts constantly.
Fine-tuning doesn’t make economic sense here. You’d be retraining continuously just to keep up, and you’d still be behind. RAG absorbs change by design. The cost difference between these two approaches in this scenario isn’t a matter of percentage points. It’s structural.
Final thoughts
RAG and fine-tuning aren’t rivals — they’re different tools for different problems, and many production systems actually use them both. RAG for retrieving the right context, fine-tuning for tone and format.
But only you know your business: how fast your data changes, what your outputs need to look like, what your compliance team will ask for. The four questions above are a guide, not a verdict. The call is yours to make.
And once you’re settled with the approach, comes the implementation — structuring your data, setting up the right infrastructure, and keeping the system aligned with how your business operates. That part we take on ourselves. So when you’re ready to discuss your AI implementation needs, just book a call, and our team will help you find the right fit.


