When LLMs Fall Short: 5 Signs You Need a Custom AI Solution
Published: – Updated:
Large Language Models (LLMs) are powerful tools in modern business, optimizing workflows, automating processes, and more. According to McKinsey’s Global Survey on AI, more than 78% of companies are now using generative AI in at least one business function (up from 55% in 2024). The potential for even more widespread use and cost optimization is thrilling, except it doesn’t work.
Well, not for everybody.
If you’ve tried to build a custom LLM or relied on an off-the-shelf solution, you’ve likely seen the cracks: AI outputs that feel increasingly detached, engineers spending hours duct-taping prompts to patch hallucinations, and teams asking, “Why can’t this thing access our own data?”
These aren’t growing pains – they’re red flags pointing to the limitations of large language models in enterprise settings. They often signal that you’ve outgrown generic models and need custom AI business solutions built for your domain, data, and security constraints.
In this article, we’ll break down five clear signs that it’s time to move beyond standard LLMs and explore how custom AI solutions, including retrieval-augmented generation (RAG), bridge the gap between limited model capabilities and the complexity of real-world use cases.
Let’s get to the point.
Red flags that signal limitations of Gen AI in enterprise settings
Every engineering team has been there. The demo goes flawlessly: Your LLM answers questions, summarizes documents, and impresses stakeholders. Then users start actually using it. Performance degrades after updates. The AI confidently makes up facts. Context windows overflow with real data.
These aren’t isolated incidents, they’re symptoms of a deeper issue. Let’s unpack five common limitations of large language models (LLMs) so you can see how they line up with your situation:
#1 AI regresses over time
I bet you’ve heard stories like that, if not faced them yourself. An AI system handled customer inquiries perfectly last month. Now it struggles with the same questions it once answered flawlessly. This isn’t a bug – it’s a fundamental limitation known as catastrophic forgetting, which occurs when AI models learn new information.
The business impact hits immediately. The AI assistant that used to onboard customers now fumbles basic tasks after a fine-tuning update for sales. Updates made to improve invoice processing cause errors in legal clause classification. Every enhancement in one area risks breakage in another, leading to a constant loop of retraining and firefighting.
This happens because generic LLMs can’t learn new tasks without partially “forgetting” previous ones. As complexity grows, so does the support burden, and user confidence drops. Your teams find themselves constantly retraining systems or accepting declining performance on critical workflows – clear indicators that you need custom AI solutions development tailored to your business requirements.
#2 Your AI starts sounding like every other AI system
Another issue with LLMs is that their responses often start to lose their human-like quality. They become more formulaic, repetitive, and disconnected from natural conversation. And let me assure you, it’s not your imagination. This is all model collapse, a process where AI systems trained on increasingly AI-generated content begin to mimic other AI systems rather than human expertise.
The root cause is a feedback loop. As more AI-generated content floods the internet, future model updates incorporate this synthetic data. The outcome is rather sad, business applications start to suffer as responses become templated, lose conversational flow, and feel artificial to users.
For example, customer support bots lose their conversational tone and start sounding like scripts. Sales automation platforms generate outreach that feels stiff and obviously machine-generated. All these points are undermining personalization and trust, things that custom AI software solutions could solve.
#3 Context window exhaustion in real applications
When users work with large language models, they often feed them all the documents they have, hoping for a spot-on summary or analysis. However, they soon discover these models run out of context, and fast.
While many models can now handle much longer text inputs (from 4K to 200K tokens), with some newer models, like Llama 4, supporting up to 10 million tokens, real-world tasks still involve documents that exceed even these limits. When working with thousands or millions of documents, we definitely exceed any context window, no matter how large. Multi-turn customer support conversations exhaust memory after a few interactions. Document analysis tasks require reading entire contracts or product manuals, far beyond token limits. Research tools need to pull insights from dozens of sources, not one PDF at a time.
While RAG helps by selecting only the most relevant documents and staying within token limits, this still doesn’t solve the deeper issue: lack of state management. Standard LLMs can’t remember what a user said in a previous session, can’t track decisions across conversations, and can’t build a persistent understanding of preferences or project context. Despite the improvements.
This is a huge deal-breaker for systems that require reasoning over time, whether it’s an AI assistant for enterprise clients, an agent coordinating internal workflows, or a tool meant to personalize outputs beyond a single request. To overcome this, some businesses go even further – exploring solutions for creating AI agents with custom memory management systems that retain context across sessions and support more intelligent, multi-step workflows.
#4 AI model lies or LLM hallucination
Which one of you has never made a mistake? Probably no one. So, what can we expect from technologies that mimic the human brain? Still, when an AI system not only makes errors but also confidently generates specifications for products that don’t exist or provides elaborate explanations for concepts it knows nothing about, it becomes a serious concern. This behavior is known as hallucination.
The outcome of such convincing deception turns into an e-commerce system that describes imaginary products in detail. Legal tools cite cases that were never published. Financial models produce an analysis based on fictional trends. And customer support bots walk users through steps that lead nowhere – all with full confidence.
This happens because LLMs are designed to predict the next word based on patterns in data, prioritizing coherence over correctness. Many developers have tried various workarounds: prompt engineering, multi-agent validation systems, and complex verification workflows. While these methods can help reduce hallucinations, they transform simple queries into expensive, multi-step processes that add complexity, increase costs, and still can’t guarantee 100% accuracy.
#5 Domain knowledge gaps
If you worked long enough with LLMs or other GenAI tools, you’ve probably noticed that no amount of prompt engineering can teach them about your company’s proprietary terminology, internal processes, or industry-specific compliance requirements. And the problem isn’t just training techniques. It’s all because models are built on publicly available data.
General-purpose LLMs lack organization-specific context. They don’t understand your legacy systems, can’t access your internal documentation, and miss the nuances of your industry’s compliance landscape. For example, legal teams often struggle when AI systems fail to interpret specialized contract language, ignore jurisdiction-specific precedents, or misunderstand internal document review workflows.
This is where the choice between custom AI solutions vs. pretrained models becomes critical – especially when your business requires integration with proprietary protocols, deep understanding of internal workflows, or strict adherence to industry-specific regulations.
Okay, so what now? We forget about LLMs and get back to manual? We can, but what for if there’s a solution, also known as RAG.
What is Retrieval Augmented Generation, and how it bridges the gap
RAG in AI stands for Retrieval-Augmented Generation – a system architecture that enhances large language models by incorporating external knowledge sources into the generation process. The retrieval-augmented generation (RAG) overview reveals a fundamental shift in how AI systems manage information. It operates through a two-phase workflow: a retrieval phase, which performs query-driven searches across external knowledge bases, and a generation phase, which produces context-aware responses by combining the retrieved information with the LLM’s capabilities.
From a business perspective, retrieval-augmented generation architecture directly addresses the limitations that often push companies toward custom AI solutions. RAG retrieves relevant information from vector databases and injects it into prompts, providing the model with the current context. This approach can be further enhanced through hybrid methods – combining vector-based retrieval with live API calls or database queries – to ensure access to both stored knowledge and real-time information, thereby eliminating the knowledge cutoff constraints inherent in standard models. It also answers the eternal question “how to reduce hallucinations in LLM” by grounding responses in real sources and working around context limitations by passing only the most relevant information to the model.
What is retrieval-augmented generation in AI?
At a high level, retrieval-augmented generation combines two powerful AI capabilities: searching for information and generating human-like responses. Instead of relying on a model’s static knowledge alone, RAG connects it to a dynamic knowledge base, making outputs more accurate, up-to-date, and trustworthy.
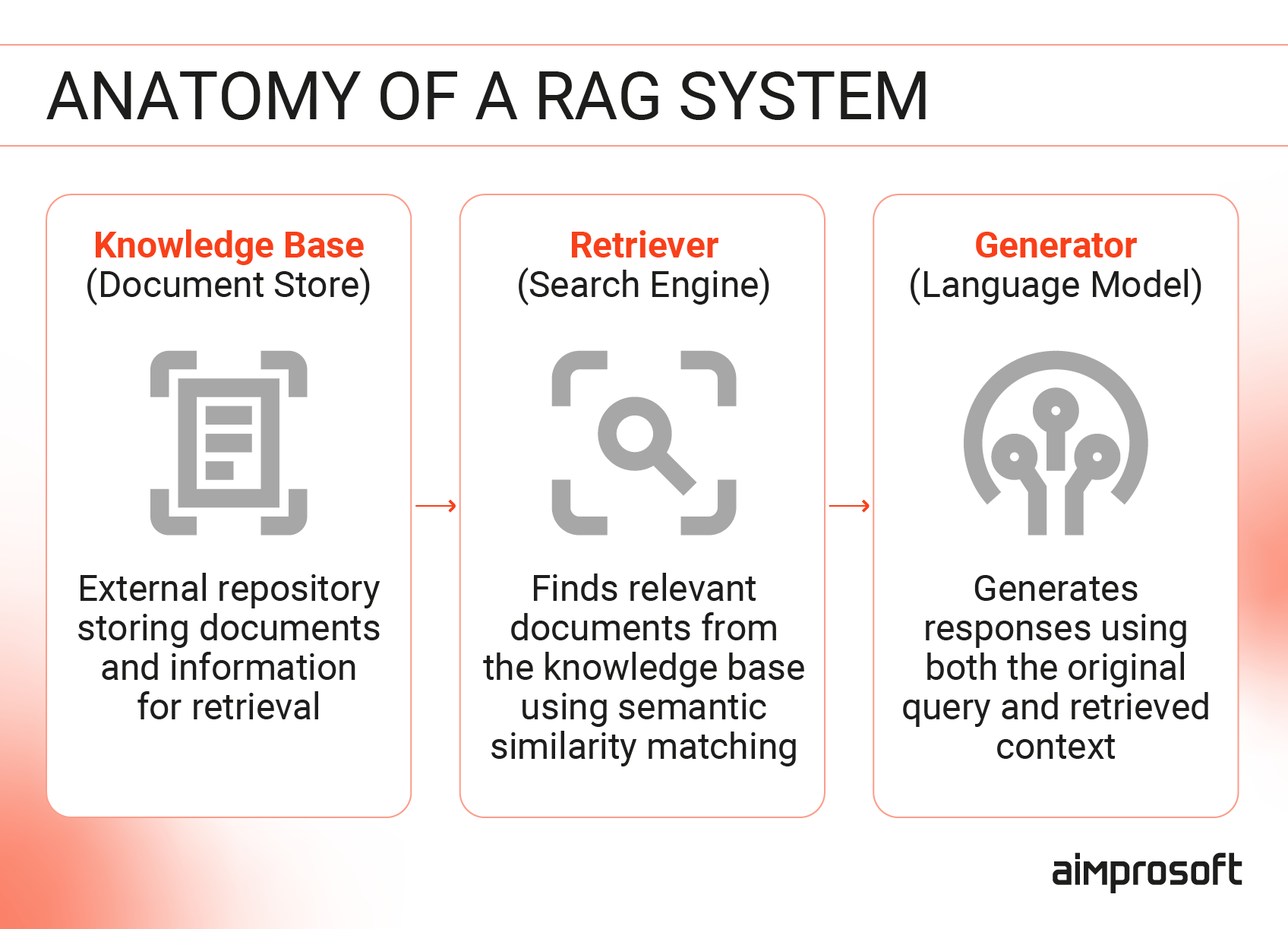
But building custom AI solutions for business isn’t just plug-and-play. It requires thoughtful engineering across several components, each playing a key role in making RAG useful, fast, and reliable in production environments. This is where custom AI/ML solutions become particularly valuable, as they can be tailored to specific business needs and data structures.
1. Document preprocessing and chunking
RAG systems begin by segmenting documents into semantically coherent chunks – typically 100 to 500 tokens each – while preserving context boundaries and attaching structural metadata. The size of these chunks directly affects how well the system finds relevant information: chunks that are too small might miss the full context, while chunks that are too large might include irrelevant details that confuse the AI. Done right, this step prevents context fragmentation and lays the foundation for accurate, relevant responses downstream, especially in cases where precision and traceability matter.
2. Vector database integration
Once documents are chunked, they’re converted into mathematical representations called embeddings and stored in a vector database. Unlike traditional keyword search, which can miss meaning and relies on exact matches, vector similarity captures semantic relationships, enabling the system to return relevant results even when users don’t use precise terminology.
For example, when a user searches for “expense reimbursement,” the system can find relevant documents even if your company policy uses terms like “travel cost recovery” or “expenditure compensation.” This allows natural language queries to perform well, even in complex, domain-specific environments where language varies.
3. Query processing and intent recognition
However, even with semantic understanding, user queries are often ambiguous or underspecified. For instance, a prompt like “What’s our policy?” could refer to anything from HR to security or customer service. Query processing helps identify the user’s intent, expands the terminology used, and selects the right search strategy before hitting the database.
So next time an employee asks, “What’s our policy?” the system will analyze context clues (user’s department, recent activity, or conversation history) to determine whether they’re asking about HR policies, security protocols, or customer service guidelines. It then searches the appropriate document sections rather than returning everything containing “policy.”
4. Hybrid retrieval and reranking
While vector search excels at understanding meaning, it’s not perfect on its own. Sometimes you need both approaches to work together. Modern RAG systems combine semantic search (via vectors) with traditional keyword-based approaches, such as BM25, along with business-specific filtering rules.
Vector search might find documents about “data protection” when you search for “privacy policy,” but if you’re specifically looking for “GDPR compliance,” exact keyword matching ensures you don’t miss documents with that precise legal term. This hybrid approach balances context sensitivity with precision, which is critical in use cases like legal or healthcare, where specific terms and definitions matter just as much as general meaning.
5. Context assembly and token management
In RAG systems, once the right documents or text chunks are retrieved from potentially thousands of sources, they need to be assembled into a final prompt that the model can understand. The problem is that LLMs can only process a limited amount of information at once – even the most advanced ones like Llama 4, with 10 million token capacity, eventually hit their limits.
That means RAG has to prioritize which pieces of context are most important. If irrelevant content is included, critical insights get pushed out, leading to weaker or even misleading answers. When done right, this step ensures the model focuses only on what’s relevant, resulting in responses that are accurate, focused, and consistent, even in complex business scenarios.
6. Response generation and grounding
Finally, the LLM generates an answer, but here’s what makes RAG different: every response is “grounded” in the actual documents retrieved. Grounding means the AI’s answer is directly tied to specific sources, not just pulled from its general training knowledge.
This may involve formatting responses with inline citations, highlighting confidence levels, or applying consistency checks against source material. Like: “According to the Q3 financial report, revenue increased 15% [Source: Q3-2024-earnings.pdf, page 3.]” For teams working in dynamic environments, custom adaptive AI solutions ensure outputs evolve with your policies, data, and compliance needs. By grounding every response in verified sources, RAG provides one of the most effective LLM hallucination mitigation techniques available today. It helps turn AI from a “black box” into a transparent research assistant that shows its work.
RAG vs Gen AI: Which one do you need?
Let’s start with the question everyone’s thinking about: Why not just use ChatGPT or Claude for everything?

Standard LLMs are tempting because they work out of the box. When you ask an LLM a question, the process is straightforward: Your query gets tokenized, processed through neural networks, and answered using the model’s pre-trained knowledge. No setup, no integration headaches, no custom infrastructure. Your team can start experimenting today with content summarization, brainstorming sessions, or basic Q&A. For many companies, this is exactly what they need, especially when you’re just testing the waters or handling low-risk tasks.
But here’s where things get interesting. What happens when your legal team needs to analyze contracts using your company’s specific clause library with thousands of documents and billions of pages? Or when customer support needs to reference your latest product documentation? Or when compliance requires every AI response to be traceable to approved sources?
These aren’t use cases for generic tools – they call for custom machine learning & AI solutions that align with your domain, data sources, and regulatory environment. That’s the job for RAG.
Instead of hoping a generic model knows about your business, RAG connects directly to your documents, databases, and knowledge systems. Every answer comes with receipts. Every response reflects your current reality, not some training data from two years ago. These are only some of the benefits of RAG over traditional LLMs.
But the real question isn’t “Retrieval-Augmented Generation vs Large Language Models.” It’s “What does your business actually need?” If you’re drafting emails and generating ideas, standard LLMs are probably perfect. If you’re making decisions that affect revenue, compliance, or customer trust, you need something that knows your business inside and out.
This isn’t the type of decision to make on the spot. But whether you’re looking for custom AI software solutions, need retrieval augmented generation explained in the context of your business, or want to explore how this approach fits your data workflows, we’re here to consult you on the complexities of enterprise AI deployment.
Contact us and we’ll get back to you.